GraphQL @connection
What is Serverless ?
- Serverless is a cloud computing execution model where the cloud provider dynamically manages the allocation and provisioning of servers. A serverless application runs in stateless compute containers that are event-triggered, ephemeral (may last for one invocation), and fully managed by the cloud provider.
What is Serverless applications?
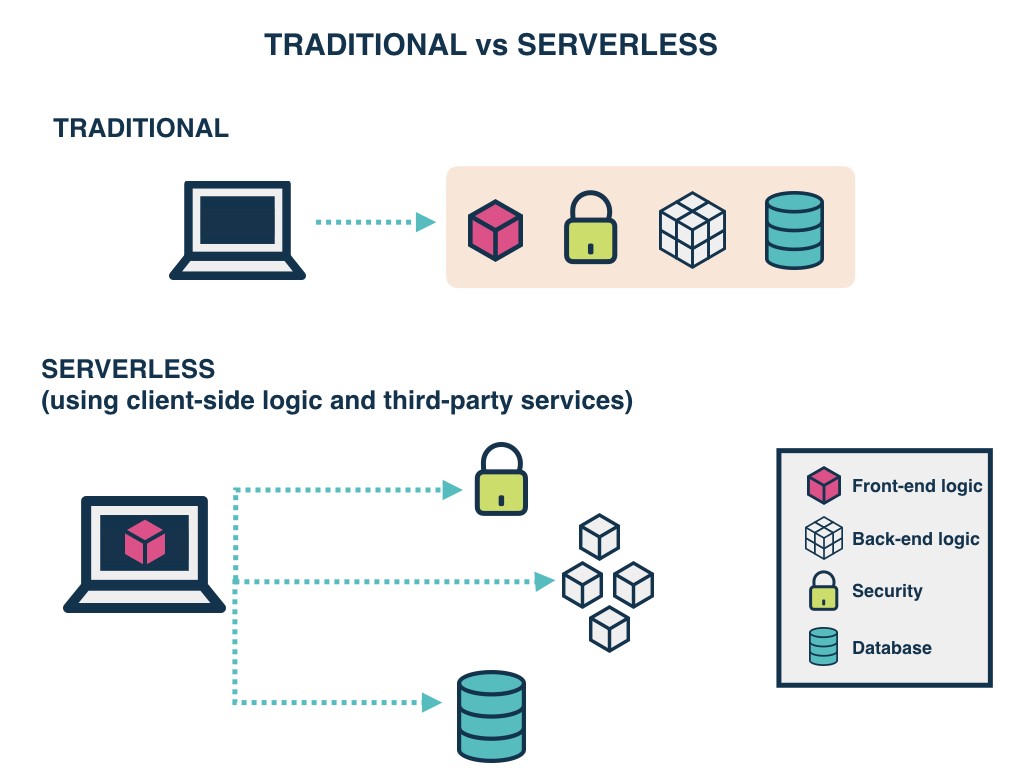
- Serverless applications are event-driven cloud-based systems where application development rely solely on a combination of third-party services, client-side logic and cloud-hosted remote procedure calls (Functions as a Service).
cloud providers examples
Traditional vs. Serverless Architecture
-
Serverless Architecture is better than Traditional based on price
-
Traditional Architecture is better than Serverless based on Networking
- The downside is that Serverless functions are accessed only as private APIs. To access these you must set up an API Gateway.
-
based on 3rd Party Dependencies Serverless Architecture is better than Traditional based
-
Setting up different environments for Serverless is as easy as setting up a single environment.
-
Traditional Architecture is better than Serverless based on Timeout
-
Scaling process for Serverless is automatic and seamless, but there is a lack of control or entire absence of control. While automatic scaling is great, it’s difficult not to be able to address and mitigate errors related to new Serverless instances.
-
Functions as a Service (FaaS)
FaaS is an implementation of Serverless architectures where engineers can deploy an individual function or a piece of business logic.
-
Principles of FaaS:
- Complete management of servers
- Invocation based billing
- Event-driven and instantaneously scalable
-
Key properties of FaaS:
-
Independent, server-side, logical functions
FaaS are similar to the functions you’re used to writing in programming languages, small, separate, units of logic that take input arguments, operate on the input and return the result.
-
Stateless
With Serverless, everything is stateless, you can’t save a file to disk on one execution of your function and expect it to be there at the next. Any two invocations of the same function could run on completely different containers under the hood.
-
Ephemeral
FaaS are designed to spin up quickly, do their work and then shut down again. They do not linger unused. As long as the task is performed the underlying containers are scrapped.
-
Event-triggered
Although functions can be invoked directly, yet they are usually triggered by events from other cloud services such as HTTP requests, new database entries or inbound message notifications. FaaS are often used and thought of as the glue between services in a cloud environment.
-
Scalable by default
With stateless functions multiple containers can be initialised, allowing as many functions to be run (in parallel, if necessary) as needed to continually service all incoming requests.
-
Fully managed by a Cloud vendor
AWS Lambda, Azure Functions, IBM OpenWhisk and Google Cloud Functions are most well-known FaaS solutions available. Each offering typically supports a range of languages and runtimes e.g. Node.js, Python, .NET Core, Java.
-
The Serverless App
Serverless Frameworks
- Serverless Framework (Javascript, Python, Golang)
- Apex (Javascript)
- ClaudiaJS (Javascript)
- Sparta (Golang)
- Gordon (Javascript)
- Zappa (Python)
- Up (Javascript, Python, Golang, Crystal)
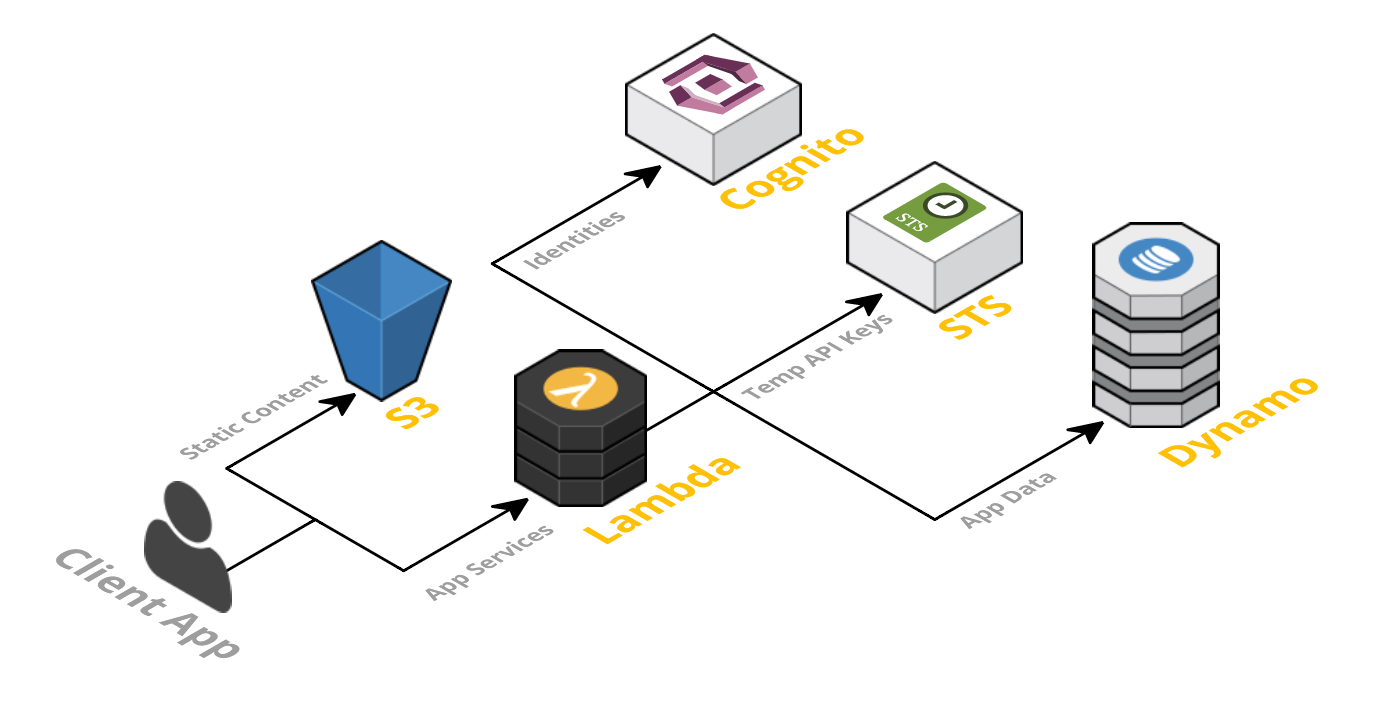
AWS Amplify
How AWS Amplify works
.86135eef1e1961cf5cc41fba8c1a5fc46bf38cf2.png)
GraphQL @connection section
Add relationships between types @connection
-
Definition
directive @connection(keyName: String, fields: [String!]) on FIELD_DEFINITION -
Usage
-
Relationships between types are specified by annotating fields on an
@modelobject type with the@connectiondirective. -
The
fieldsargument can be provided and indicates which fields can be queried by to get connected objects. ThekeyNameargument can optionally be used to specify the name of secondary index (an index that was set up using@key) that should be queried from the other type in the relationship. -
When specifying a
keyName, thefieldsargument should be provided to indicate which field(s) will be used to get connected objects. IfkeyNameis not provided, then@connectionqueries the target table’s primary index.
-
-
Has one
-
In the simplest case, you can define a one-to-one connection where a project has one team:
type Project @model { id: ID! name: String team: Team @connection } type Team @model { id: ID! name: String! } -
You can also define the field you would like to use for the connection by populating the first argument to the fields array and matching it to a field on the type:
type Project @model { id: ID! name: String teamID: ID! team: Team @connection(fields: ["teamID"]) } type Team @model { id: ID! name: String! } -
After it’s transformed, you can create projects and query the connected team as follows:
mutation CreateProject { createProject(input: { name: "New Project", teamID: "a-team-id"}) { id name team { id name } } }
-
-
Has many
-
The following schema defines a Post that can have many comments:
type Post @model { id: ID! title: String! comments: [Comment] @connection(keyName: "byPost", fields: ["id"]) } type Comment @model @key(name: "byPost", fields: ["postID", "content"]) { id: ID! postID: ID! content: String! } -
After it’s transformed, you can create comments and query the connected Post as follows:
mutation CreatePost { createPost(input: { id: "a-post-id", title: "Post Title" } ) { id title } } mutation CreateCommentOnPost { createComment(input: { id: "a-comment-id", content: "A comment", postID: "a-post-id"}) { id content } } -
And you can query a Post with its comments as follows:
query getPost { getPost(id: "a-post-id") { id title comments { items { id content } } } }
-
-
Belongs to
-
you add a connection from Comment to Post since each comment belongs to a post:
type Post @model { id: ID! title: String! comments: [Comment] @connection(keyName: "byPost", fields: ["id"]) } type Comment @model @key(name: "byPost", fields: ["postID", "content"]) { id: ID! postID: ID! content: String! post: Post @connection(fields: ["postID"]) } -
After it’s transformed, you can create comments with a post as follows:
mutation CreatePost { createPost(input: { id: "a-post-id", title: "Post Title" } ) { id title } } mutation CreateCommentOnPost1 { createComment(input: { id: "a-comment-id-1", content: "A comment #1", postID: "a-post-id"}) { id content } } mutation CreateCommentOnPost2 { createComment(input: { id: "a-comment-id-2", content: "A comment #2", postID: "a-post-id"}) { id content } } -
And you can query a Comment with its Post, then all Comments of that Post by navigating the connection:
query GetCommentWithPostAndComments { getComment( id: "a-comment-id-1" ) { id content post { id title comments { items { id content } } } } }
-
-
Many-to-many connections
-
You can implement many to many using two 1-M
@connections, an@key, and a joining @model. For example:type Post @model { id: ID! title: String! editors: [PostEditor] @connection(keyName: "byPost", fields: ["id"]) } # Create a join model and disable queries as you don't need them # and can query through Post.editors and User.posts type PostEditor @model(queries: null) @key(name: "byPost", fields: ["postID", "editorID"]) @key(name: "byEditor", fields: ["editorID", "postID"]) { id: ID! postID: ID! editorID: ID! post: Post! @connection(fields: ["postID"]) editor: User! @connection(fields: ["editorID"]) } type User @model { id: ID! username: String! posts: [PostEditor] @connection(keyName: "byEditor", fields: ["id"]) } -
add a connection between them with by creating a PostEditor object as follows:
mutation CreateData { p1: createPost(input: { id: "P1", title: "Post 1" }) { id } p2: createPost(input: { id: "P2", title: "Post 2" }) { id } u1: createUser(input: { id: "U1", username: "user1" }) { id } u2: createUser(input: { id: "U2", username: "user2" }) { id } } mutation CreateLinks { p1u1: createPostEditor(input: { id: "P1U1", postID: "P1", editorID: "U1" }) { id } p1u2: createPostEditor(input: { id: "P1U2", postID: "P1", editorID: "U2" }) { id } p2u1: createPostEditor(input: { id: "P2U1", postID: "P2", editorID: "U1" }) { id } } -
You can query a given user with their posts:
query GetUserWithPosts { getUser(id: "U1") { id username posts { items { post { title } } } } } -
Also you can query a given post with the editors of that post and can list the posts of those editors, all in a single query:
query GetPostWithEditorsWithPosts { getPost(id: "P1") { id title editors { items { editor { username posts { items { post { title } } } } } } } }
-
-
Alternative definition
directive @connection(name: String, keyField: String, sortField: String, limit: Int) on FIELD_DEFINITION -
Limit
-
The default number of nested objects is 100. You can override this behavior by setting the limit argument. For example:
type Post @model { id: ID! title: String! comments: [Comment] @connection(limit: 50) } type Comment @model { id: ID! content: String! }
-
-
Generates
In order to keep connection queries fast and efficient, the GraphQL transform manages global secondary indexes (GSIs) on the generated tables on your behalf when using @connection